1.Процедура лексического анализа
2.Сканер на основе инженерной
импровизации
3.Сканер на основе детерминированного
автомата
4.Таблично-управляемые программы
Лексический анализ (ЛА)- это часть общего процесса компиляции, в ходе которого выполняется распознавание и перевод во внутреннее представление конструкций языка типа 3 по Хомскому. Такие конструкции называют лексемами. Наиболее типичные классы лексем: имена (идентификаторы), константы, служебные слова. Процедура или сопрограмма, выполняющая ЛА, называется лексическим анализатором или сканером.
Внутреннее представление лексемы: <Код
класса лексемы> <Индекс>. Индекс - это индекс
элемента в соответствующей таблице сканера,
который содержит всю детальную информацию о
лексеме (тип, значение, ...), которая будет
необходима на этапе генерации кода и не
существенна на этапе грамматического разбора.
Обычно сканер строит три таблицы: имён, констант
и служебных слов. Пример.
Вход: if Key <= Middle then
Index := Down+1
Выход:
Таблица имён: 1) Key, 2) Middle, 3) Index, 4) Down, 5) ... .
Таблица констант: 1) 1, 2) ... .
Таблица служебных слов: 1) if, 2) <=, 3) then, 4) :=, 5) +, 6) ...
.
Сканер приводит программу к некоторому стандартному виду, что существенно упрощает её последующий грамматический разбор.
Различают прямоработающий и непрямоработающий сканеры. Прямоработающий сканер возвращает очередную лексему входа и её класс. Прямоработающий сканер в общем случае должен обладать способностью заглядывания вперёд. Непрямоработающий сканер проверяет относится ли очередная лексема входа к заданному классу и возвращает соответствующее булевское значение и саму лексему, если относится. Непрямоработающий сканер удобен в тех случаях, когда легко предвидеть к какому классу должна принадлежать очередная лексема.
Ниже приведён текст процедуры сканера GetLex вместе с соответствующим драйвером. Такой сканер можно взять за основу сканера ассемблера для учебной ЦВМ.
program TstGetLex;
type TLex = (NAME,NUM,SPEC,OTHER); {Тип классов лексем}
var Ch,sCh: Char; {Текущая и следующая литеры входа}
FIn: Text; {Файл входа}
CLex: TLex; {Класс лексемы}
Lex: string; {Значение лексемы}
procedure GetCh; {Получить очередную литеру входа}
begin
if not Eof(FIn) then
begin Ch:=sCh; Read(FIn,sCh) end
else
Ch:=';';
end; {GetGh}
procedure GetLex(var CLex: TLex; var Lex: string);
{Получить очередную лексему входа}
const FIG = ['0'..'9']; {Цифры}
LET = ['A'..'Z','a'..'z']; {Буквы}
SYM = ['+','-',',',';']; {Спецлитеры}
BLN = [' ', #9, #10, #13]; {Пробельные литеры}
begin
while Ch in BLN do GetCh; {Пропуск пробельных литер}
Lex:=Ch;
if Ch in SYM then
begin CLex:=SPEC; GetCh; Exit end;
if Ch in FIG then
begin
GetCh;
while Ch in FIG do
begin Lex:=Lex+Ch; GetCh end;
CLex:=NUM;
Exit;
end;
if Ch in LET then
begin
GetCh;
while Ch in LET+FIG do
begin Lex:=Lex+Ch; GetCh end;
CLex:=NAME;
Exit;
end;
CLex:=OTHER; GetCh;
end; {GetLex}
begin
Assign(FIn,'fin.pas'); Reset(FIn);
GetCh; GetCh;
while (Ch<>';') or (sCh<>';') do
begin
GetLex(CLex,Lex);
WriteLn(ord(CLex),' ',Lex);
end;
Close(FIn);
end.
Обратите внимание на то, что реализация процедуры GetCh предусматривает возможность заглядывания на одну литеру вперёд. Это может быть полезно для распознавания двухлитерных лексем, например "<=".
Нам известно, что для анализа сентенций регулярных грамматик можно использовать детерминированный автомат. В качестве примера рассмотрим программную реализацию автомата Мили, которую можно использовать в качестве сканера для распознавания имён и числовых констант целого типа без знака.
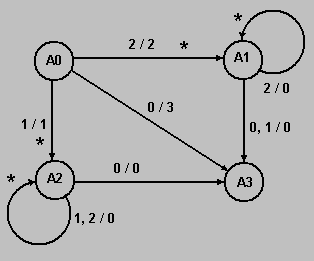
Функционирование автомата Мили задаётся формулами A(t+1) = fi(A(t),X(t)) и Y(t) = psi(A(t),X(t)), где t - автоматное время; A - алфавит состояний, включая исходное состояние автомата A0; X - алфавит входных сигналов; Y - алфавит выходных сигналов.
Введём понятие класса литеры: 1 - буквы, 2 - цифры, 0 - другие. Подобным же образом закодируем классы лексем: 1 - имя, 2 - число, 3 - другие. Далее будем считать, что X = {0, 1, 2} и Y = {0, 1, 2, 3}. Определив алфавиты входных и выходных сигналов, построим граф автомата, распознающего имена и целые числа без знака:
На графе обозначения дуг в числителе определяют условия перехода, а в знаменателе - выходные сигналы автомата. Звёздочкой отмечены те дуги автомата, переход по которым должен сопровождаться чтением следующей литеры входа. Непосредственно по графу автомата строим процедуру реализации сканера.
procedure GetLex(var CLex: Integer; var Lex: string);
const fi: array[0..2,0..2] of Integer = ( {Таблица переходов}
{ X A0 A1 A2 }
{ 0 } ( 3, 3, 3 ),
{ 1 } ( 2, 3, 2 ),
{ 2 } ( 1, 1, 2 ));
psi: array[0..2,0..2] of Integer = ( {Таблица выходов}
{ X A0 A1 A2 }
{ 0 } ( 3, 0, 0 ),
{ 1 } ( 1, 0, 0 ),
{ 2 } ( 2, 0, 0 ));
Aa = 0; {Исходное состояние автомата}
Az = 3; {Конечное состояние автомата}
var A: Integer; {Текущее состояние автомата}
function X(Ch: Char): Integer; begin ... end; {Класс литеры}
begin
A:=Aa; Lex:='';
while A <> Az do
begin
case psi[X(Ch),A] of
0: ;
1: CLex:=1;
2: CLex:=2;
3: CLex:=0;
end; {case}
A:=fi[X(Ch),A];
if A<>Az then
begin
Lex:=Lex+Ch;
GetCh;
end;
end;
end; {GetLex}
В некоторых случаях по ходу работы сканера выполняют и необходимые семантические преобразования. Так например, если с дугами автомата A0, A1 и A1, A1 ассоциировать соответственно действия V := ord(Ch) - ord(' ') и V := 10 * V + ord(Ch) - ord(' '), то это приведёт к формированию значения константы во внутреннем представлении.
Сканер, реализованный в предыдущем пункте, относится к числу программ, которые принято называть таблично-управляемыми. Такой способ построения программ характерен для СПО.
Copyright г Барков Валерий Андреевич, 2000