В.А. Барков
(Конспект лекций)
1. Архитектура машины I386
2. Регистры процессора
3. Принципы адресации
4. Сегментация
5. Виртуальная сегментная адресация
6. Запись дескрипторов GDT на ассемблере
7. Механизм защиты данных
8. Системные дескрипторы
9. Назначение LDT
10. Call gates
11. Мультизадачность
12. Прерывания
13. Paging
14. Внутренний cache
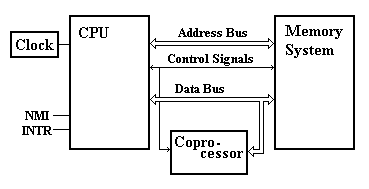
Рис. 1.1. Архитектура машины I386
Длина машинного слова - 32 р. Процессор имеет два входа аппаратного прерывания - NMI (немаскируемое) и INTR (маскируемое).
Общие регистры (32 р.): EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP.
Сегментные регистры (16 р., *): CS, DS, SS, ES, FS, GS.
Регистры состояния (32 р.): EFLAGS, EIP.
Регистры защищённого режима (protected
mode):
GDTR (48 р., *) - Global Descriptor Table (GDT) Register;
IDTR (48 р., *) - Interrupt Descriptor Table (IDT) Register;
LDTR (16 р., *) - Local Descriptor Table (LDT) Register;
TR (16 р., *) - Task Register. Содержит селектор TSS - Task State
Segment.
Регистры управления: CR0..CR3.
Регистры тестирования и отладки: DR0..DR7.
Примечание. Звёздочкой отмечены регистры, имеющие теневую часть.
Важные биты некоторых регистров:
EFLAGS[17] = VM - Virtual 8086 Mode;
EFLAGS[14] = NT - Nested Task flag;
EFLAGS[13..12] = IOPL[1..2] - I/O Privilege Level (PL);
EFLAGS[9] = IF - Interrupt Enable flag. Маскирует внешние
аппаратные прерывания.
CR0[31] = PG - Бит, который включает Paging.
CR0[0] = Protect Enable. Бит переключения процессора в
защищённый режим.
32-разрядное машинное слово определяет линейное (linear) адресное пространство размером 2^32 байтов (4 Гб). Обычно существует требование создания возможности выполнять задачи, размер которых превышает размер физического (physical) адресного пространства. Задачу отображения линейного адресного пространства на физическое решает paging. Реальное содержание линейного адресного пространства хранится на диске в виде последовательных страниц памяти. В каждый момент времени лишь некоторая их часть находится в ОП. ОС по мере необходимости освобождает не очень нужные страницы ОП, копируя их содержимое в соответствующие страницы на диске, и на освободившееся место загружает новые. При этом paging должен обеспечивать правильное преобразование каждого линейного адреса в соответствующий физический адрес ОП. ОС также должна перехватывать обращения к страницам, которым ещё нет соответствия в физической памяти, и подгружать их. Будем считать, что если paging выключить, то физические адреса просто будут совпадать с линейными.
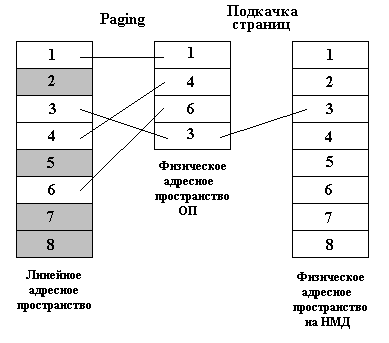
Рис. 3.1. Paging
Кроме того естественно желание предоставить каждой задаче собственное адресное пространство, которое принято называть виртуальным (virtual). Это позволяет писать код задач совершенно независимо от его последующего размещения в линейном адресном пространстве. Задача преобразования виртуальных адресов в линейные наиболее просто решается на основе идеи сегмента (segment) памяти. Размер сегмента и его расположение в линейном адресном пространстве удобно определить с помощью специальной структуры данных - дескриптора сегмента памяти (descriptor).

Рис. 4.1. Формат дескриптора сегмента памяти
Base (32 р.) - линейный адрес
определяемого сегмента;
Limit (20 р.) - уменьшенный на единицу размер сегмента
(доступны адреса 0 .. Limit);
G - Granularity. Значение единицы измерения размера
сегмента в поле Limit (0 - 1 б; 1 - 4 Kб);
B - определяет режим работы процессора. Для
сегментов данных B = 0, если размер сегмента не
превышает 64 Kб, и B = 1 в противном случае. В случае
сегментов кода этот бит называется D. При D = 0
процессор выполняет инструкции с 16-разрядными
адресами, и с 32-разрядными - в противном случае;
AVL - Available (вспомогательный). Его смысл определяет
программист. Обычно используется при сборке
мусора:
Access rights - права доступа:
P - Present. Указывает на присутствие сегмента в
физической памяти;
DPL - Descriptor PL (0..3);
S - Segment. Tип дескриптора. Для дескрипторов
сенгментов памяти S = 1;
Type:
0 - Read only data segment;
1 - Read/write data segment;
3 - Read/write expand-down data segment. Используется для стеков
(доступны адреса Limit+1 .. FFFFFFFFH);
4 - Execute only code segment;
5 - Execute/readable code segment.
Другие возможные значения здесь не
рассматриваются.
A - Accessed. Устанавливается в единицу, если соответствующий селектор был загружен в сегментный регистр. Используется для контроля за частотой обращения к сегментам.
Селектор - структура данных, которая используется для обращения к дескрипторам. Формат селектора (16 р.):

Index - индекс дескриптора в
соответствующей дескрипторной таблице;
TI - Table Indicator bit (0 - GDT; 1 - LDT);
RPL - Requested PL.
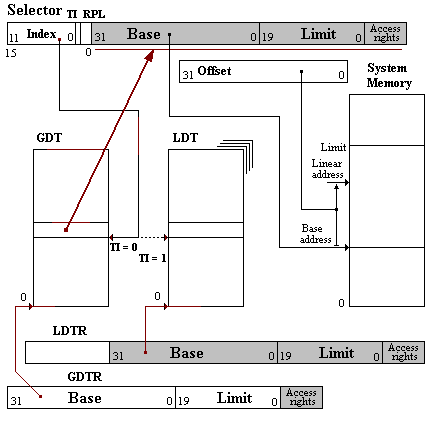
Рис. 4.2. Схема преобразования виртуальных адресов в линейные
На основе сегментации может быть организована виртуальная сегментная адресация. Рассмотрим пример её реализации. Пусть объём физической ОП составляет 1000 Кб. Предположим также, что в режиме совмещения необходимо выполнять три задачи - A, B и C, причём каждая содержит 200 Кб исполняемого кода и 200 Кб данных. На рис. 5.1 показаны два варианта размещения соответствующих сегментов, которые возникают последовательно по ходу выполнения задач.
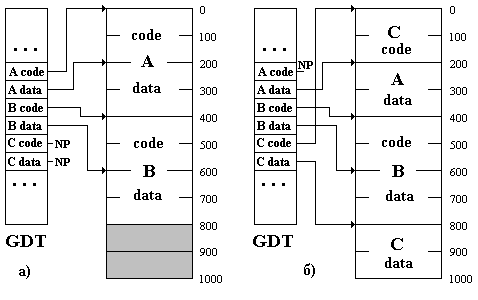
Рис. 5.1. Виртуальная сегментная адресация
Мы видим, что сегмент кода задачи A и сегмент кода задачи C занимают одно и то же место в ОП, и поэтому должны загружаться с диска по мере переключения с задачи на задачу. Отметим, что предпочтительнее загружать именно код, а не данные, так как последние могут изменяться в ходе выполнения задачи, а это приводит к необходимости их сохранения при переключении с задачи на задачу.
Преимущества и недостатки виртуальной
сегментной адресации:
+ Простота разработки приложений.
+ Возможность "одновременного" выполнения
нескольких задач, суммарный объём которых может
превышать объём имеющейся физической ОП.
+ Возможность защиты памяти.
+ Возможность совмещения кода некоторых
сегментов разными задачами (sharing).
+ Возможность устранения эффекта внешней
фрагментации. Небольшие свободные
фрагменты памяти легко могут быть объеденены в
один фрагмент, имеющий практическое значение -
для этого достаточно переместить существующие
сегменты памяти.
- Усложнение архитектуры ЦВМ и ОС.
Следует отметить гибкость, которую даёт
сегментация:
1) Сегментацию можно игнорировать (для этого надо
создать один сегмент кода и один сегмент данных,
размеры которых равны размеру ОП).
2) Можно использовать полную сегментацию (каждый
объект в своём сегменте).
3) Можно использовать промежуточные формы
сегментации.
descr struc limit dw 0 ; Граница (биты 0..15) base_l dw 0 ; База (биты 0..15) base_m db 0 ; База (биты 16..23) attr_1 db 0 ; Байт атрибутов 1 attr_2 db 0 ; Байт атрибутов 2 base_h db 0 ; База (биты 24..31) descr ends . . . ; GDT gdt_null descr <0,0,0,0,0,0> ; Нулевой дескриптор gdt_data descr <data_size-1,0,0,92h> ; Сел. 8, сег. данных gdt_code descr <code_size-1,0,0,9Ah> ; Сел.16, сег. кода . . .
Значение поля DPL дескриптора сегмента памяти определяет уровень привилегий этого сегмента - 0 (высший) .. 3 (низший). Говорят также о внутренних и внешних кольцах защиты. Существует также понятие текущего уровня привилегий CPL (Current PL) - это значение поля RPL селектора в CS.
Условие доступа к данным: DPL >= max( RPL, CPL), где RPL (Requested PL) - это запрашиваемый уровень привилегий - значение поля RPL того селектора, который используется для выбора дескриптора сегмента памяти. Зависимость доступа от RPL позволяет ОС оперативно корректировать возможность доступа к данным в зависимости, например, от источника получения селектора. Важно, что при этом не надо изменять код процедуры, выполняющей доступ.
Условие доступа к сегментам кода ещё жёстче: DPL = CPL. Передача управления на другие уровни возможна только при посредничестве специальных сиcтемных объетов, которые называют шлюзами (gates), но и при этом доступ во внутренние кольца может быть только execute only.
Кроме того, введено понятие привилегированных
команд процессора - команд, которые можно
выполнять только на уровне 0. Вот список наиболее
важных привилегированных команд:
LGDT - Load GDT register,
LIDT - Load IDT register,
LLDT - Load LDT register,
LTR - Load Task Register.
Перечисленные элементы механизма защиты определяют его лишь в главных чертах.
Системные дескрипторы определяют системные объекты - такие, как LDT, TSS, шлюзы. Следует отметить, что селекторы этих дескрипторов нельзя загружать в сегментные регистры, т.е. они не позволяют работать с этими объектами как со структурами данных. Для этих целей эти же объекты (это касается LDT и TSS) должны быть определены как обычные сегменты данных с теми же значениями полей Base и Limit в дескрипторах, которые принято называть алиасами.

Рис. 8.1. Формат системных дескрипторов
Type:
2 - LDT;
5 - Task gate;
9 - TSS. Type[1] = Busy. Если бит Busy установлен, то Type = B
(Busy TSS);
C - Call gate;
E - Interrupt gate;
F - Trap gate.
Поля Selector и Offset дескрипторов шлюзов определяют точку в линейном адресном пространстве, в которую передаётся управление через данный шлюз. Поле Dword count используется только в Call gate.
Назначение других элементов структуры системных дескрипторов рассмотрим в разделах, в которых обсуждается их использование.
На рис. 9.1 даны два варианта организации адресного пространства двух задач - A и B.
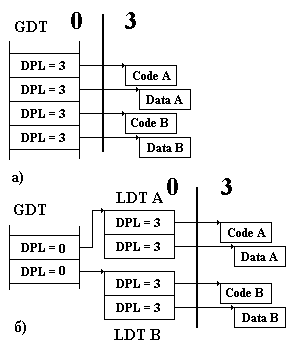
Рис. 9.1. Назначение LDT
В варианте а) код задачи A не может изменить состояние GDT, так как она находится во внутреннем кольце защиты, но может "подделать" селектор и обратиться как к данным, так и к коду задачи B. В варианте б) в GDT размещены дескрипторы двух LDT, из которых только один может быть выбран загрузкой соответствующего селектора в LDTR, а это означает принципиальную недостижимость сегментов задачи B из задачи A и наоборот.
Передача управления через них происходит при выполнении инструкции CALL. Поле Dword Count определяет количество двойных слов, которые передаются из стека уровня вызывающей программы в стек уровня вызываемой. Такой механизм передачи параметров необходим по соображениям защиты данных. Эти же соображения приводят к необходимости иметь собственный стек на каждом уровне защиты. Для возврата в вызывающую программу используется команда RET.
Селектор дескриптора текущей TSS содержится в TR.
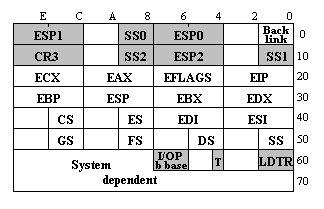
Рис. 11.1. Формат TSS
Минимальный размер TSS составляет 104 байта. Содержание TSS достаточно очевидно. На рисунке серым отмечены поля, которые не сохраняют соответствующие значения в TSS старой задачи, но используются для установки соответствующих величин из TSS новой задачи. Значения этих полей могут быть изменены только на нулевом уровне привилегий. Поле Back link содержит селектор TSS предыдущей задачи. Незаполненные клетки соответствуют полям с нулевыми значениями.
Переключение задач могут инициировать четыре
события:
1) Текущая задача выполнила инструкцию CALL или JMP с
селектором дескриптора TSS.
2) Текущая задача выполнила инструкцию CALL или JMP с
селектором дескриптора Task gate.
3) Текущая задача выполнила инструкцию IRET и в EFLAGS
NT = 1.
4) Происходит прерывание с Task gate в IDT.
При переключении состояние процессора сохраняется в TSS старой задачи, а новое состояние формируется на основе TSS новой задачи. Это в общем плане. Точный же алгоритм переключения задач достаточно велик и мы здесь ограничимся, в основном, интуитивными представлениями. Отметим лишь некоторые нюансы.
Если переключение выполняется по инструкции JMP, то бит Busy дескриптора TSS старой задачи сбрасывается, а новой - устанавливается.
Если причиной переключения была инструкция CALL или прерывание, то бит Busy дескриптора TSS старой задачи остаётся установленным в 1. Бит NT в EFLAGS тоже устанавливается в 1.
Если переключение произошло в результате выполнения инструкции IRET, то бит Busy дескриптора TSS старой задачи устанавливается в 0.
Режим выполнения инструкции IRET зависит от значения бита NT. Если он установлен, то выполняется обратное переключение на задачу, селектор дескриптора которой находится в поле Back link TSS. В противном случае вполняется обычный возврат из программы обработки прерывания (через стек).
Классификация: Interrupts ( Hardware Interrupts, Exceptions ( Traps, Faults, Aborts ) ).
Каждый источник прерывания имеет номер прерывания, который определяет шлюз в IDT, определяющий в свою очередь программу обработки прерывания - обработчик прерывания (Interrupt Handler). CS:EIP и EFLAGS прерванной программы, а при Exceptions ещё и код ошибки (Error code), помещаются в стек перед передачей управления обработчику прерывания. В IDT можно включать только Interrupt gates, Trap gates и Task gates. Task gates в IDT работают точно так же, как и в GDT. Interrupt gates и Trap gates различаются только тем, что в первом случае происходит очистка бита IF в EFLAGS, а во втором - он остаётся без изменения. Для выхода из обработчика прерывания служит инструкция IRET, причём Error code надо предварительно вытолкнуть из стека. Интепретация Error code зависит от номера прерывания.
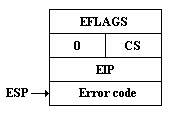
Рис. 12.1. Состояние стека в момент входа в обработчик прерывания
Traps (ловушки) - в стек помещается CS:EIP инструкции, следующей за инструкцией, в ходе которой возникает прерывание. Все программные прерывания (инициируемые инструкцией INT) обрабатываются как ловушки, причём DPL дескриптора шлюза должен быть равен уровню привилегий, на котором выполняется инструкция INT.
Faults (отказы) - в стек помещается CS:EIP инструкции, в ходе выполнения которой возникла ошибка. Предполагается, что если её устранить в ходе выполнения обработчика прерывания, то после выхода из него программа продолжит нормальную работу так, как будто прерывания и не было. Классический пример - прерывание 11 (Segment not present).
Aborts (аварии) - серъёзная ошибка с возможной утерей части контекста. Информация об ошибке может быть не достоверна.
Shut down - выключение процессора.
Таблица прерываний
| Interrupt number |
Class | Description |
| 0 | Fault | Divide error |
| 1 | Fault or Trap | Debugger interrupt |
| 2 | Interrupt | Nonmaskable interrupt |
| 3 | Trap | Breakpoint |
| 4 | Trap | Interrupt on overflow (INTO) |
| 5 | Fault | Array boundary violation (BOUND) |
| 6 | Fault | Invalid opcode |
| 7 | Fault | Coprocessor not available |
| 8 | Abort | Double fault |
| 9 | Abort | Coprocessor segment overrun |
| 10 | Fault | Invalid TSS |
| 11 | Fault | Segment not present |
| 12 | Fault | Stack exception |
| 13 | Fault | General protection violation |
| 14 | Fault | Page fault |
| 15 | Reserved | |
| 16 | Fault | Coprocessor error |
| 17 | Fault | Alignment check |
| 18 - 31 | Reserved | |
32 - 255 |
Interrupt or Trap |
System dependent |
Физическая память делится на страницы по 4 Kб (page frames). Адрес страницы (page frame address) - старшие 20 битов физического адреса любого байта, принадлежащего странице.
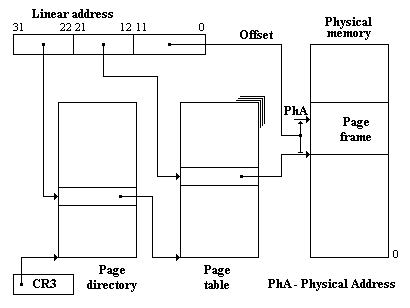
Рис. 13.1. Схема преобразования линейных адресов в физические

Рис. 13.2. Формат элемента таблицы страниц
Каталог страниц (page directory) и таблица страниц (page table) состоит из элементов (page table entry) одинакового формата. Бит P (Present) определяет наличие страницы в физической памяти. Другие биты мы здесь не рассматриваем - они необходимы для организации виртуальной страничной памяти. Так принято называть этот метод адресации. Слово "виртуальный" здесь имеет более общее значение и не имеет буквального отношения к виртуальной адресации в сегментах памяти. Адреса страниц и адрес в CR3 - физические.
Одна таблица страниц "обслуживает" 4 Mб физической ОП. Например, для ОП объёмом 32 Mб необходимо 8 таблиц страниц, что требует, включая необходимую страницу для каталога страниц, 36 Kб памяти!
К недостакам метода следует отнести то, что ему присущ эффект внутренней фрагментации памяти, который выражается в том, что последняя страница из числа выделяемых задаче может оказаться заполненной лишь частично.
Другой недостаток состоит в том, что из-за необходимости обращения к элементам таблиц страниц резко увеличивается количество обращений к ОП. С целью его уменьшения в архитектуру машины включено специальное буферное ЗУ (TLB - translation lookside buffer), в котором могут находиться 32 наиболее часто используемых элемента таблицы страниц. Утверждается, что TLB удовлетворяет до 98% обращений к ОП.
Вводится в архитектуру процессора с целью увеличения его производительности.
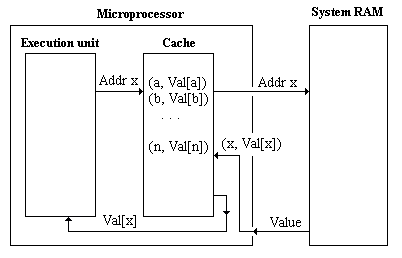
Рис. 14.1. Обращение к ОП с cache